Proposed Coding Framework
A general scheme of the proposed residual deep animation codec. The components of the proposed system include:
- Frame prediction by animation
- Low bitrate spatial residual coder
- Low bitrate temporal residual coder
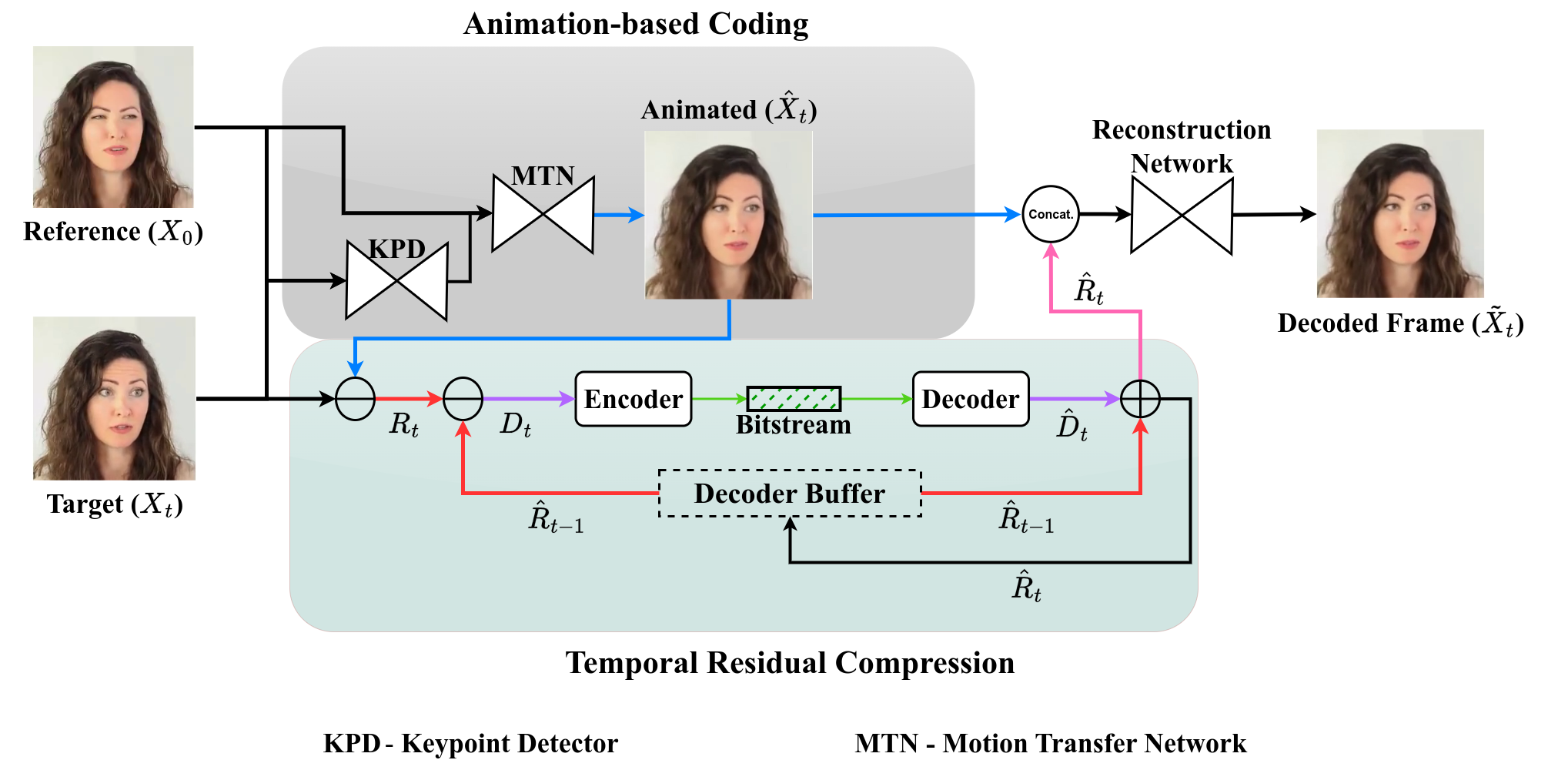
We address the problem of efficiently compressing video for conferencing-type applications. We build on recent approaches based on image animation, which can achieve good reconstruction quality at very low bitrate by representing face motions with a compact set of sparse keypoints. However, these methods encode video in a frame-by-frame fashion, i.e., each frame is reconstructed from a reference frame, which limits the reconstruction quality when the bandwidth is larger.
Instead, we propose a predictive coding scheme which uses image animation as a predictor, and codes the residual with respect to the actual target frame. The residuals can be in turn coded in a predictive manner, thus removing efficiently temporal dependencies.
Our experiments indicate a significant efficiency gain at low bitrates, in excess of 70% compared to the HEVC video standard and over 30% compared to VVC, on a dataset of talking-head videos.
A general scheme of the proposed residual deep animation codec. The components of the proposed system include:
HEVC - Low latency HEVC configuration of the reference HM TEST MODEL
DAC - Our original deep animation codec
H-DAC- Animation-based coding with the scalable base layer coded with HEVC
RDAC- Predictive coding framework with animation and spatio-temporal residual learning
At very low bitrates (below 10 kbps) the reconstruction quality of RDAC is lower bounded by DAC i.e. the worst possible quality is that of the frame created by animation only. At this bitrate range, the residual coder is contrained to code only the residual texture and style. Therefore, the reconstructed video does not have feature level differences with the output of animation-only codec.(DAC). Our main objective is to preserve the quality of the animated frame at the lowest bitrate range. Subsequently, when additional bitrate is allocated to the predictive residual coder, the output reconstruction quality is improved, a behaviour that is expected from a practical video codec.
The visual quality of hybrid animation codec (HDAC) and predictive animation codec (RDAC) are both higher than HEVC in this bitrate range. However we observe a convergence in quality between HDAC and RDAC such that in most of the video frames, the quality is largely similary. The main advantage of RDAC over HDAC is that it is end-to-end trainable and has a bitrate interpolation for frame residual coding. This allows for continous variation between the minimum and maximum lambda values. On the other hand, HDAC is trained with fixed quality base layer frames and thus has discrete RD points.
@article{konuko2020dac,
author = {Konuko, Goluck and Lathuilière, Stéphane and Valenzise, Giuseppe},
title = {Ultra-low bitrate video conferencing using Deep Image animation models},
journal = {ICASSP},
year = {2020},
}
@article{konuko2022hdac,
author = {Konuko, Goluck and Lathuilière, Stéphane and Valenzise, Giuseppe},
title = {H-DAC: Hybrid coding with Deep Animation Models for Ultra-Low Bitrate Video Conferencing},
journal = {ICIP},
year = {2022},
}
@article{konuko2023rdac,
author = {Konuko, Goluck and Lathuilière, Stéphane and Valenzise, Giuseppe},
title = {Predictive Coding for Animation-Based Video Compression},
journal = {ICIP},
year = {2023},
}
There is a number of works released concurrent or subsequent to our initial work in the domain of animation-based video communication. They provide valuable insight into computer-vision and model optimization aspects that could inspire great curiousity into this line of work.
Face-vid2vid: Proposes a neural talking-head video synthesis model with novel-view rendering capability and demonstrates its application to video conferencing.
Motion-SPADE Explores quality and bandwidth trade-offs for approaches based on static landmarks, dynamic landmarks or segmentation maps for image animation and proposes designs for mobile-compatible model architecture for low-latency chat applications.
Beyond Keypoint Coding: Temporal Evolution Inference with Compact Feature Representation for Talking Face Video Compression Proposes a novel sparse representation for animation-based coding. We updated our own keypoint quantization and entropy coding processes to match those used by this work.